2) Maskininlärning
I den här lektionen får du lära dig om maskininlärning. Mycket viktigt för resten av kursen.
Lektionen handlar om:
- Maskininlärning - att träna modeller
- Neuronnät – som vi kommer att använda
- Hur en färdig modell kan användas
I början av kursen använder vi modeller som bygger på neuronnät. Senare i kursen använder vi andra modeller men principen för maskinlärning och träning är densamma.
Maskininlärning - träning
Vid maskininlärning tränas en protypmodell i en dator med en stor mängd data. Träningen görs med hjälp av färdig programvara (kallad programmet i texten som följer). Exempel som vi kommer att stöta på är Keras/TensorFlow och scikit-learn.
Data kan till exempel vara bilder på katter och hundar så att modellen kan lära sig skilja på (bilder av) katter och hundar. Maskininlärning för stora modeller med stora datamängder kan ta mycket lång tid i form av datortid – ibland dagar eller mera. Vi ska nu titta på hur maskininlärning funkar.

❶ Först läser programmet in en otränad prototyp av modellen. Prototypmodellen har en viss arkitektur men innehållet är bara slumpade värden. De framslumpade värdena ska sedan tränas upp så att modellen blir användbar. För våra appar i kursen använder vi djupinlärning (deep learning). Det innebär ganska stora modeller med många lager – modellen är djup. Djupinlärning tog fart först efter 2012 och är nu mycket populär. Allt är alltså ganska nytt. Bättre metoder för träning och bättre hårdvara har gjort djupinlärning möjlig. Men vi tränar inte några modeller för djupinlärning i vår kurs (med något undantag). Vi använder färdigtränade modeller främst från Google.
❷ Programmet läser in ett antal bilder. Till varje bild hör en etikett (label) som talar om vad bilden visar. Etiketten sätts manuellt genom att en människa tittar på bilden och bestämmer om det är en katt eller hund. Det görs innan träningen börjar. Bilderna läses inte in en och en utan i form av batchar (satser). En batch kan t.ex. vara 16 bilder eller 1024 bilder. Batchar användes för att få parallellbearbetning så att träningen går mycket snabbare.
❸ Batchen av bilder stoppas in i modellen och vi får ett resultat för varje bild (katt eller hund) dvs många resultat för batchen.
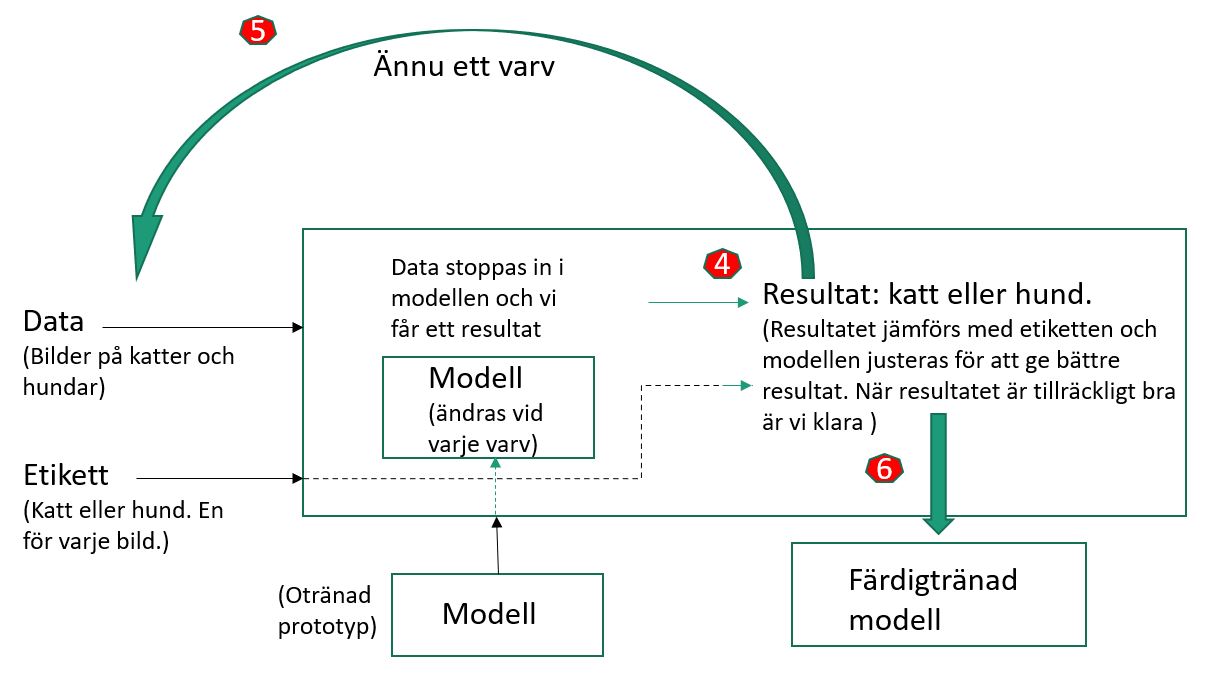
❹ Resultatet (för varje bild) jämförs med etiketten som hör till bilden. Nu justeras värdena inuti modellen så att resultatet ska bli bättre vid nästa varv. Just hur värdena ska justeras är den verkligt svåra biten. När forskarna löste det problemet blev maskininlärning riktigt användbart.
❺ Nu är det dags för ett nytt varv i träningen. Hur många varv behövs? Det beror på hur mycket data (hur många bilder) vi har och hur mycket modellen behöver tränas. Säg att vi har 100,000 bilder och vår batch-storlek är 1000. Då måste vi köra 100 varv för att gå igenom alla bilder en gång. Men för att få ett bra resultat måste vi kanske gå igenom alla bilder 100 gånger. Då krävs alltså 100*100 = 10,000 varv! Kan ta lång tid! Beror på hur stora bilderna är, hur stor modellen är och hur snabb datorn eller GPUn är. Mest används grafikprocessorer (GPU:er) för träningen för att kunna få snabb parallellbearbetning. Jag använder ibland en gammal speldator och GPUn ger ungefär 10 ggr snabbare träning jämfört med att bara använda CPUerna.
❻ När resultatet är tillräckligt bra eller inte blir bättre avbryter vi träningen och vi har nu en färdigtränad modell. Modellen är en fil med en viss struktur. Modellen kan användas i applikationer av olika slag.
Neuronnät

Neuronen och neuronnät är ganska gamla – från 1950-talet. Neuronen är alltså en nod i nätet. Först efter ungefär 2012 har användningen av neuronnät tagit fart. Pga bättre algoritmer och hårdvara (GPUer). Bilden visar ett tunt neuronnät med bara ett lager. Lägg till flera lager och du får ett djupt neuronnät. Fully Connected-lager (som i figuren) används ofta bara på slutet av ett nät som annars ofta består av CNN-lager. CNN är helt enkelt snabbare och bättre än FC. CNN är den vanligaste typen av lager i de nät som vi ska använda. Men i de modeller som vi ska använda finns också andra lagertyper än FC och CNN.
Vikterna/parametrarna/värdena (olika namn bara) som tränas finns inuti noderna/neuronerna. OBS Viktigt: Allt är tal (numeriska värden): indata (pixelvärdena i bilden, pixel=bildpunkt), vikterna och utdata (t.ex. 1 betyder katt, 0 betyder hund). Allt är nämligen matematik. Indata (pixelvärdena) omformas av modellen till 0 (hund) eller 1 (katt) i utdata.
Artificiella neuronnät

Hur neuronen och neuronnäten kom till är intressant. De sågs till en början som förenklade modeller av hur vår hjärna och vårt nervsystem fungerar – därav namnen. Men vi vet helt enkelt inte hur vår hjärna fungerar i detalj och ännu mindre hur den tränas. Det är säkert inte på samma sätt och med samma metoder som vi tränar våra modeller. Hjärnan är ju helt överlägsen jämfört med vad vi kan åstadkomma med AI!
Rent filosofiskt kan vår hjärna ses som en modell som tränas hela livet med sinnesintryck (syn, hörsel osv). Det lilla barnet har en ganska otränad hjärna/modell som sedan tränas genom åren.
Så det korrekta namnet är artificella neuronnät.
Repetition modell/neuronnät

En repetition av modeller eller neuronnät som för oss är samma sak.
- Modellen byggs upp av lager. Antalet lager kan vara stort – hundratals
- En vanlig lagertyp är CNN
- Många lager innebär att modellen är djup
- I varje lager finns noder.
- I varje nod finns vikter som tränas vid maskininlärningen men som är fasta vid användning i en applikation (färdigtränad modell)
- Indata, vikter, och utdata är tal.
- Utdata beräknas från indata med hjälp av vikterna i alla lager
Användning av färdig modell
Den färdigtränade modellen kan användas i en AI-app (i dator, mobil osv) för att ge svar/resultat/förutsägelse (prediction). En app är ett datorprogram – en applikation. Att som programmerare använda en färdig modell i en app är enklare och kräver mindre kunskap jämfört med att träna modellen. I vår kurs använder vi färdigtränade modeller för djupinlärning. Du kommer bara att träna en modell för djupinlärning vid ett tillfälle – när du ska träna en modell så att den kan skilja på lätet från katt (mjau) och hund (vov). AI applikationer kan finnas i datorer, mobiler, robotar, bilar osv.

❶ Appen läser först in modellen och sedan data (en bild). Gärna en bild som inte användes vid träningen – annars är det fusk! OBS: Här hanteras normalt en bild i taget och inte en batch av bilder som vid träningen.
❷ Data (bilden) stoppas in i modellen och vi får ett resultat.
❸ Ett svar från en färdigtränad modell kan komma mycket snabbt – på bråkdelar av en sekund. Alltså mycket snabbare än vid träning av modellen. Vi har ju bara en bild, ”ett varv”, och vi justerar inga vikter i modellen – den knepiga biten är borta. Hur snabbt beror på hur stor bilden är, hur stor modellen är och hur snabb datorn eller mobilen är.
Summering
I den här lektionen lärde du dig om maskininlärning dvs att träna en modell.
En modell är för oss just nu ett neuronnätverk – men det finns förstås andra typer av nätverk som vi kommer att se längre fram.
CNN är en vanlig lagertyp i våra nätverk. Bra för t.ex. bildbehandling.
Allt är tal (numeriska värden): indata, vikterna och utdata.
En färdigtränad modell kan användas i applikationer i datorer, mobiler, bilar, robotar osv.
Nästa lektion: Om tillämpningar.
