19) Agenter och robotar
Reinforcement learning (RL)
Den här lektionen handlar om Reinforcement learning (RL) – på svenska ”förstärkt inlärande”. RL är ganska annorlunda mot vad vi sett tidigare i kursen. RL används till exempel för att lära en robotarm att göra en speciell uppgift eller att träna det överordnade systemet i en självkörande bil. Men också för att lära en agent spela ett spel.
Vi ska se på två RL-metoder:
Policy-baserad. En agent balanserar en stolpe som står på en vagn genom att knuffa vagnen till höger eller vänster.
Q-learning. Agenten spelar Snake.
RL-metod: policy-baserad. Exempel: Stolpe-på-vagn
Vi såg ett exempel på RL i videon – ”stolpe-på-vagn”. Mycket översiktligt kan ett RL-problem beskrivas så här:
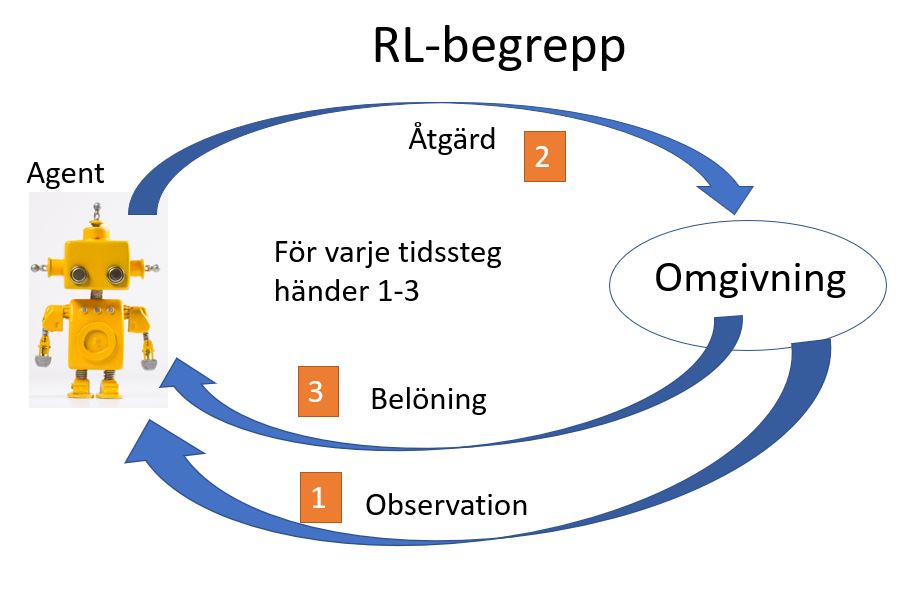
Agenten växelverkar med omgivningen. För varje tidssteg får agenten information från omgivningen om läget. Utgående från informationen tar agenten ett beslut om en åtgärd. Omgivningen ger ”kanske” en belöning till agenten beroende på om åtgärden var lyckad eller inte.
Målet för vår agent är att få så stor belöning som möjligt.
För ”stolpe-på-vagn” gäller:
| Omgivning | En vagn på ett spår med begränsad längd och på vagnen står en stolpe |
| Observation | 1) Vagnens position, 2) vagnens hastighet, 3) vinkeln för stolpens lutning, 4) hastigheten med vilken vinkeln ändras |
| åtgärd | Knuffa vagnen från vänster eller höger sida (alltid med samma kraft) |
| Belöning | För varje steg får agenten en belöning = 1. |
Träna agenten
Hur kan nu vår agent tränas? Här används en metod med ett policy-nätverk och vår metod sägs vara policy-baserad.
Vad är nu en policy? En policy kan här sägas vara det som bestämmer agentens åtgärd vid ett viss tidssteg - vi får åtgärden från policy-nätverket genom att ge observations-värdena som indata.Vårt policy-nätverk är ett mindre neuronnätverk som tränas så att agenten när träningen är klar kan fatta beslutet höger eller vänster genom att ge de fyra observationerna som indata till nätverket/modellen och få ett beslut (klassificering) höger eller vänster. Men först måste vår modell/nätverk/agent (ungefär samma sak) tränas men observera att vårt policy-nätverk används under hela träningen och förbättras efter varje iteration.
Träningen går till så här (vi startar med slumpade vikter i modellen):
- Ge de fyra observationsvärdena till modellen
- Slumpa fram en åtgärd (höger eller vänster) utgående från resultatet från modellen. Resultatet tas inte direkt från modellen utan ändras lite slumpmässigt. Tänk på att i början ger inte modellen bra resultat och skulle dåliga resultat användas rakt av skulle det inte bli något lärande.
- Uppdatera omgivningen med åtgärden d.v.s. knuffa från höger eller vänster enligt beslutet
- Spara ett antal storheter (bl.a. utdata från modellen och åtgärden) från tidssteget. Ska användas senare när modellen ska förbättras
- Spara också belöningen på samma sätt
- Upprepa 1-5 ett antal gånger (episoder). En episod är ett ”spel” d.v.s. agenten kör vagnen tills den misslyckas eller maximalt 500 steg. För oss är standardvärdet för antalet episoder 20.
- När 20 episoder är klara uppdatera modellen (vikterna) med hjälp av de sparade värdena från 4 och 5.
- Upprepa 1-7 ett antal gånger, kanske 20 gånger.
Att göra 1-8 tar en stund men kan göras i webbläsaren (finns som övningsuppgift). När du tränar agenten ser du en kurva som kan likna den här:
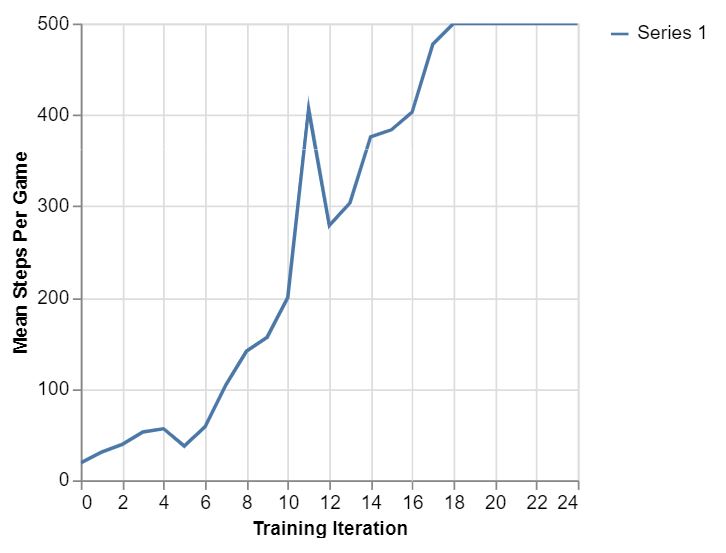
Kurvan visar medelvärdet för antal steg under olika iterationer. Börjar på 20 ungefär och når sedan 500 (kan aldrig bli högre) efter 19 iterationer. I de första iterationerna misslyckas agenten ganska snabbt men blir sedan skickligare.
Exemplet stolpe-på-vagn är relativt enkelt och kan lösas utan AI med vanlig programmering där åtgärden beräknas utgående från observationerna. Men det är som vi såg för bildigenkänning mm – blir uppgiften svårare är det helt enkelt omöjlig eller åtminstone mycket dyrt att lösa problemet utan AI/RL.
Verklig träning
Hur kan man träna ett system för en självkörande bil? Agenten gör ju många misstag i början av träningen. Att låta den otränade agenten träna ute i trafiken går förstås inte – är både farligt och dyrt. Ett vanligt sätt är att först träna agenten i en simulator ungefär som vi gjorde för stolpe-på-vagn. Nästa steg kan vara att träna utan simulator men i en kontrollerad miljö utan ”främmande” trafik – med eller utan mänsklig förare. Efter mycket träning kan agenten träna vidare i verklig trafik men då med en förare som hela tiden är beredd att ta över.
RL-metod: Q-learning. Exempel: Snake
Vi såg i videon hur agenten spelade Snake med hjälp av Q-värden. Men hur får man fram Q-värdena? Genom träning förstås.
Vårt RL-problem ”Spela Snake” kan beskrivas översiktligt precis som för stolpe-på-vagn. Vi har agent, omgivning, observation, åtgärd, och belöning. Målet för agenten är att få så stor belöning som möjligt.
| Omgivning | En spelplan med 9x9 rutor som innehåller ormen och en frukt. Frukten placeras ut slumpmässigt. |
| Observation | Agenten får efter varje steg reda på vad som finns i varje ruta på spelplanen |
| åtgärd | Gå en ruta framåt, till vänster eller till höger. |
| Belöning | För varje steg (framåt, vänster eller höger) får agenten en belöning. äta frukt: +10. Ett steg utan att äta: -0.2. Huvud träffar vägg eller svans (spelet slut): -10. |
Hur kan nu vår agent tränas så att vi får våra Q-värden? Och varför heter det Q-värden?
Om du kommer ihåg hur agenten tränades för stolpe-på-vagn så tränade man upp ett litet neuronnätverk som agenten sedan kunde använda för sina beslut/åtgärder. Man omformulerade problemet till att bli ett problem där man kunde träna ett neuronnätverk för att lösa problemet.
Ytligt sett behandlas Snake-problemet på samma sätt det vill säga låt agenten spela Snake med hjälp av ett nätverk – början slumpartat sedan bättre. Spara info från spelet för att förbättra vikterna i nätverket.
Men det finns mycket som skiljer lösningen för stolpe-på-vagn från lösningen för Snake - se tabellen.
| Snake | Stolpe-på-vagn | |
|---|---|---|
| Svårighetsgrad | Svårare. Kan inte tränas i webb-läsaren. | Lättare. Kan tränas i webb-läsaren. |
| RL-metod | Q-learning | Policy-baserad |
| Nätverk/modell | Ett mera komplicerat CNN som kallas DQN (Deep Q-Network) | Litet ”fully connected” |
| Statisk? | Nej. Ormen växer. | Ja | Belöning | Varierar | Lika hela tiden | MDP? | Ja | Nja? |
MDP (Markov Decision Process)
MDP (Markov Decision Process) säger att omgivningen efter nästa steg bestäms helt av aktuell omgivning samt vilken åtgärd som utförs. Det verkar ju ganska självklart men gäller inte alltid. Om MDP gäller så förenklas vårt problem.
För Snake gäller MDP men även för ett mera komplicerat spel som schack. För Snake eller schack behöver vi bara veta innehållet i varje ruta (tillståndet) för att stoppa spelet och sedan starta det igen kanske någon annanstans. Historien om hur vi fick innehållet i varje ruta är inte intressant.
Utgående från MDP går det att jobba vidare för att i teorin kunna beräkna Q-värden.
Q-värden
Ett Q-värde är den förväntade totala belöningen för en åtgärd vid ett givet tillstånd. För att få den totala belöningen (Q-värdet) måste spelet spelas till slut med vissa val.
Q i Q-värde står för ”quality”/kvalitet. Q-värde kallas också tillstånd-åtgärds-värde (State-Action value).
Ett stort problem är att antalet tillstånd är astronomiskt. För att lösa problemet används ett DQN (Deep Q-Network) som efter träning ger ungefärliga Q-värden.
DQN ger 3 Q-värden motsvarande framåt, vänster, höger. Indata till DQN är innehållet av varje ruta på spelplanen. DQN tränas med sparad spelhistoria från agentens tidigare försök.När agenten spelar väljer agenten alltid åtgärden som svarar mot det högsta Q-värdet.
Träna agenten
Träningen av agenten för Snake kan inte göras i webb-läsaren. Kräver alltför mycket minne. Träningen kan däremot göras med hjälp av Node.js som ju kan exekvera Javascript-kod utanför webb-läsaren. Men träningen är resurskrävande (tar lång tid). Därför använder vi en färdigtränad modell/DQN som laddas in av appen som vi körde i videon.
Stolpe-på-vagn robot
Snake kunde vi spela i en riktig miljö med hjälp av AI. Stolpe-på-vagn däremot körde vi i en simulering. är det svårt att bygga en robot som kan balansera en stolpe? Jag har forskat lite och det är kräver en del arbete.
Först kan vi förenkla problemet genom att ersätta stolpen som står på vagnen med en inverterad pendel som ska balanseras på vagnen. Det blir då enklare genom att stolpen/pendeln sitter fast i vagnen och en sensor kan läsa av vinkeln (hur mycket stolpen lutar) och hur vinkelhastigheten ändras. Roboten balanserar stolpen så att den står upprätt genom att köra fram och tillbaka.
Vår modifierade stolpe-på-vagn skiljer sig från det ursprungliga stolpe-på-vagn genom att stolpen sitter sitter fast i en axel på vagnen men också genom att roboten inte rullar friktionsfritt utan drivs av motorer. Men fallen är mycket lika.
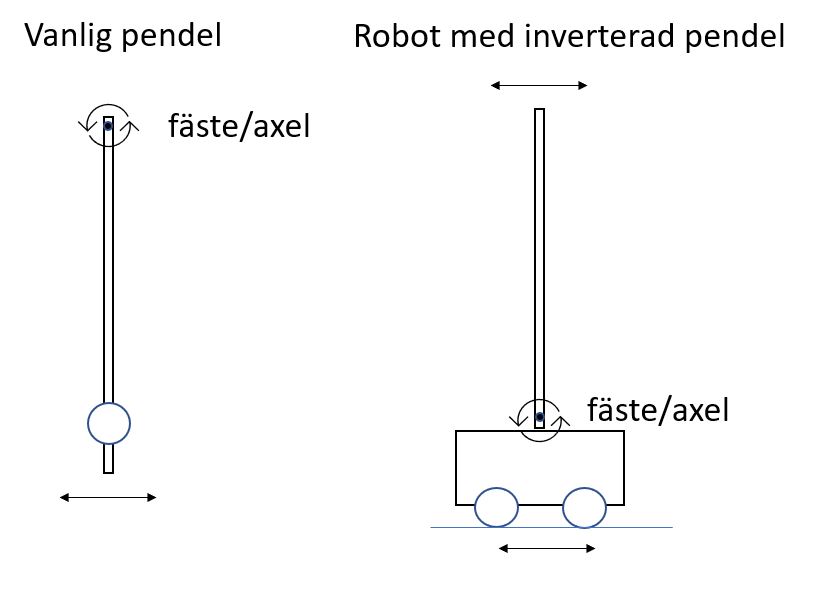
Vår robot måste kunna:
- Köra fram och tillbaka utan att avvika (alltför mycket) från en rät linje - är svårare än man kan tro
- Via sensorer hålla reda på de fyra observationsvärdena: 1) Robotens position, 2) Robotens hastighet, 3) vinkeln för pendelns lutning 4) hastigheten med vilken vinkeln ändras
- För varje tidssteg ge observationsvärdena till modellen och få tillbaka vilken åtgärd (framåt eller bakåt) som ska utföras.
Som central kontrollenhet kan en Raspberry Pi enkortsdator användas. Materialkostnaden för roboten inklusive chassi, sensorer osv blir ungefär 1500kr.
Programmeringen för roboten görs enklast i Python. Enklast är om det går att undvika träningen av roboten genom att ta modellen från vårt ursprungliga stolpe-på-vagn och låta den modellen styra valet fram eller tillbaka. Några ändringar i simuleringen måste troligtvis göras. 1) En fördröjning mellan knuffarna måste kanske läggas in. 2) Kraften i knuffen kan behöva justeras 3) Sträckan roboten kan röra sig på kan behöva ökas. Genom att skruva på värdena 1 och 2, träna modellen i simulatorn och sedan testa i roboten kan vi förhoppningsvis balansera pendeln. Ett alternativ eller komplement till att justera värdet 2 är att justera hastigheten med vilken roboten ska röra sig - det bestämmer ju hur kraftig knuffen blir.
Om vi inte kan använda den färdiga modellen återstår att träna modellen direkt i roboten. Men det kräver mycket mera arbete...
Jag gissar att den största svårigheten med vår robot är att plocka upp pendelns vinkel och ändring i vinkelhastighet på ett bra sätt.
En robot liknande vår robot (fast större) kan ses i den här videon https://youtu.be/AuAZ5zOP0yQ.
Det här är en helt annan lösning för inverterade-pendel-problemet https://youtu.be/o7Lpz_yEJgA.
Referenser
Implementeringen av appen cart-pole (i Javascript) som användes i den här lektionen finns på https://github.com/tensorflow/tfjs-examples/tree/master/cart-pole Vår app har några smärre tillägg jämfört med appen på Github.
Implementeringen av appen Snake och träningen av DQN finns på https://github.com/tensorflow/tfjs-examples/tree/master/snake-dqn
Den här lektionen är inspirerad av kapitel 11 i boken Deep Learning with Javascript Boken ger en mera utförlig men ändå ganska lättillgänglig beskrivning av RL.
Om du är intresserad av hur man kan bygga en robot finns en bra beskrivning här learn-robotics-programming-second-edition. Kan ibland fås för 5$.
Summering
I den här lektionen lärde vi oss hur agenter/robotar kan tränas med hjälp av Reinforcement learning (RL).
Vi tittade på två RL-metoder policy baserad och Q-learning.
Agenten och dess omgivning växelverkar med observationer, åtgärder och belöningar.
RL är annorlunda mot de metoder vi sett tidigare men ändå används neuronnät som modell för att styra agenten i de exempel vi tittat på.
RL har många tillämpningar till exempel i självkörande bilar eller i robotar.
